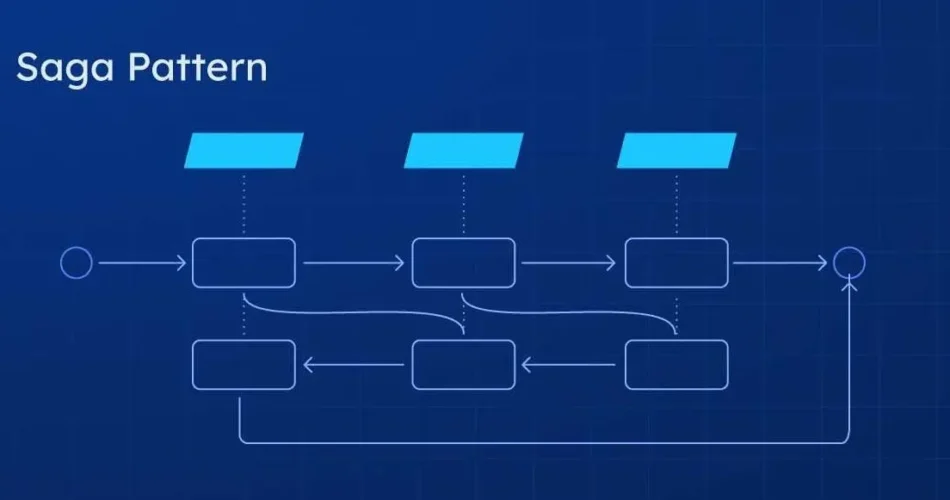
Most Saga tutorials either stop at “call service A then service B” or gloss over the annoying parts (async replies, idempotency, correlation, compensations). This post doesn’t. We’ll wire up:
- Temporal Workflow that acts as the orchestrator/state machine.
- Activities that publish commands to a message bus.
- Microservices that handle commands and publish events.
- A tiny signal-bridge that listens to events and signals the workflow.
We’ll simulate a checkout
demo-saga/
docker-compose.yml # Temporal + UI + NATS
orchestrator/
activities/publish.go # Activities publish commands to NATS
workflows/order_workflow.go
worker/main.go
signal-bridge/
main.go # NATS evt.* -> Temporal Signal
services/
order/main.go
payment/main.go
inventory/main.go
pkg/util/nats.go # tiny NATS helpers
cmd/start_workflow/main.go
The workflow publishes commands like cmd.payment.reserve. Services emit events like evt.payment.reserved. The bridge converts evt.* → Temporal Signal that wakes the workflow.
Bootstrapping infra
docker compose up -d # Temporal + Temporal UI + NATS go run ./orchestrator/worker go run ./signal-bridge go run ./services/order go run ./services/payment go run ./services/inventory go run ./cmd/start_workflow --order-id=order-1 --should-fail-inventory=true
Open Temporal UI at http://localhost:8080 and watch the steps + compensations in history.
Activities: “fire-and-forget” commands
Activities are small, retryable units. Here they publish commands to NATS. That’s it. They don’t wait for replies—because replies are events that come back later via Signals.
// orchestrator/activities/publish.go
package activities
import (
"context"
"fmt"
"demo-saga/pkg/util"
)
type Activities struct{}
func (a *Activities) PublishOrderCreate(ctx context.Context, sagaID string) error {
nc, err := util.ConnectNATS(); if err != nil { return err }
defer nc.Close()
msg := util.Msg{SagaID: sagaID}
fmt.Println("[ACT] cmd.order.create", util.MustJSON(msg))
return util.PublishJSON(nc, "cmd.order.create", msg)
}
func (a *Activities) PublishPaymentReserve(ctx context.Context, sagaID string, amount int) error {
nc, err := util.ConnectNATS(); if err != nil { return err }
defer nc.Close()
msg := util.Msg{SagaID: sagaID, Payload: map[string]interface{}{"amount": amount}}
fmt.Println("[ACT] cmd.payment.reserve", util.MustJSON(msg))
return util.PublishJSON(nc, "cmd.payment.reserve", msg)
}
func (a *Activities) PublishPaymentRefund(ctx context.Context, sagaID string) error {
nc, err := util.ConnectNATS(); if err != nil { return err }
defer nc.Close()
msg := util.Msg{SagaID: sagaID}
fmt.Println("[ACT] cmd.payment.refund", util.MustJSON(msg))
return util.PublishJSON(nc, "cmd.payment.refund", msg)
}
func (a *Activities) PublishInventoryReserve(ctx context.Context, sagaID, sku string, qty int) error {
nc, err := util.ConnectNATS(); if err != nil { return err }
defer nc.Close()
msg := util.Msg{SagaID: sagaID, Payload: map[string]interface{}{"sku": sku, "qty": qty}}
fmt.Println("[ACT] cmd.inventory.reserve", util.MustJSON(msg))
return util.PublishJSON(nc, "cmd.inventory.reserve", msg)
}
func (a *Activities) PublishInventoryRelease(ctx context.Context, sagaID string) error {
nc, err := util.ConnectNATS(); if err != nil { return err }
defer nc.Close()
msg := util.Msg{SagaID: sagaID}
fmt.Println("[ACT] cmd.inventory.release", util.MustJSON(msg))
return util.PublishJSON(nc, "cmd.inventory.release", msg)
}
func (a *Activities) PublishOrderCancel(ctx context.Context, sagaID string) error {
nc, err := util.ConnectNATS(); if err != nil { return err }
defer nc.Close()
msg := util.Msg{SagaID: sagaID}
fmt.Println("[ACT] cmd.order.cancel", util.MustJSON(msg))
return util.PublishJSON(nc, "cmd.order.cancel", msg)
}
Why this design?
- Activities are retried by Temporal on failure (network hiccups, etc.).
- We keep them simple and idempotent: publishing the same command twice should not break services (your services should de-duplicate by
sagaId).
Workflow: the state machine that waits for Signals
The workflow tells services what to do (via Activities) and blocks until the corresponding event arrives as a Signal. If anything goes wrong, we run compensations in reverse.
// orchestrator/workflows/order_workflow.go
package workflows
import (
"errors"
"fmt"
"time"
"demo-saga/orchestrator/activities"
"go.temporal.io/sdk/temporal"
"go.temporal.io/sdk/workflow"
)
type OrderInput struct {
SagaID string
Amount int
SKU string
Qty int
ShouldFailInventory bool // demo flag
}
func OrderWorkflow(ctx workflow.Context, in OrderInput) error {
ao := workflow.ActivityOptions{
StartToCloseTimeout: time.Second * 10,
RetryPolicy: &temporal.RetryPolicy{MaximumAttempts: 3},
}
ctx = workflow.WithActivityOptions(ctx, ao)
var a activities.Activities
// 1) Create order and wait for confirmation
if err := workflow.ExecuteActivity(ctx, a.PublishOrderCreate, in.SagaID).Get(ctx, nil); err != nil {
return err
}
if err := waitForEvent(ctx, "evt.order.created", in.SagaID); err != nil {
return err
}
// 2) Reserve payment; on failure, cancel order
if err := workflow.ExecuteActivity(ctx, a.PublishPaymentReserve, in.SagaID, in.Amount).Get(ctx, nil); err != nil {
return err
}
if err := waitForOneOf(ctx, in.SagaID, "evt.payment.reserved", "evt.payment.failed"); err != nil {
_ = workflow.ExecuteActivity(ctx, a.PublishOrderCancel, in.SagaID).Get(ctx, nil)
return fmt.Errorf("payment failed: %w", err)
}
// 3) Reserve inventory; on failure, refund & cancel
if err := workflow.ExecuteActivity(ctx, a.PublishInventoryReserve, in.SagaID, in.SKU, in.Qty).Get(ctx, nil); err != nil {
return err
}
if in.ShouldFailInventory {
// demo mode: the inventory service may emit a failed event
}
if err := waitForOneOf(ctx, in.SagaID, "evt.inventory.reserved", "evt.inventory.failed"); err != nil {
_ = workflow.ExecuteActivity(ctx, a.PublishPaymentRefund, in.SagaID).Get(ctx, nil)
_ = workflow.ExecuteActivity(ctx, a.PublishOrderCancel, in.SagaID).Get(ctx, nil)
return fmt.Errorf("inventory failed: %w", err)
}
// success path (you could continue to shipping here)
return nil
}
// ========== wait helpers ==========
func waitForEvent(ctx workflow.Context, eventName, sagaID string) error {
ch := workflow.GetSignalChannel(ctx, signalName(eventName, sagaID))
var payload string
ch.Receive(ctx, &payload)
if payload == "ERROR" {
return errors.New(eventName + " error")
}
return nil
}
// Waits for either a success or a failure event, returns error if failure is received
func waitForOneOf(ctx workflow.Context, sagaID, successEvt, failEvt string) error {
sCh := workflow.GetSignalChannel(ctx, signalName(successEvt, sagaID))
fCh := workflow.GetSignalChannel(ctx, signalName(failEvt, sagaID))
selector := workflow.NewSelector(ctx)
var gotErr error
selector.AddReceive(sCh, func(c workflow.ReceiveChannel, _ bool) { gotErr = nil })
selector.AddReceive(fCh, func(c workflow.ReceiveChannel, _ bool) { gotErr = fmt.Errorf("%s", failEvt) })
selector.Select(ctx)
return gotErr
}
func signalName(event, sagaID string) string {
return fmt.Sprintf("%s::%s", event, sagaID)
}
Why Signals over “async activity completion”?
Signals keep the workflow purely event-driven and easy to reason about. The services don’t need Temporal SDKs—they just publish events to the bus; the bridge converts bus → signal. It’s a simple, strong boundary.
The signal-bridge: the tiny but important adapter
Temporal workflows don’t consume NATS directly. The bridge subscribes to evt.*, pulls out the correlation ID (sagaId), and signals the correct workflow instance.
// signal-bridge/main.go
package main
import (
"context"
"encoding/json"
"fmt"
"log"
"demo-saga/pkg/util"
"github.com/nats-io/nats.go"
"go.temporal.io/sdk/client"
)
type Event struct {
SagaID string `json:"sagaId"`
Payload map[string]interface{} `json:"payload"`
}
func main() {
nc, err := util.ConnectNATS(); if err != nil { log.Fatal(err) }
defer nc.Close()
c, err := client.NewClient(client.Options{})
if err != nil { log.Fatal("temporal client:", err) }
defer c.Close()
subjects := []string{
"evt.order.created",
"evt.order.canceled",
"evt.payment.reserved",
"evt.payment.failed",
"evt.payment.refunded",
"evt.inventory.reserved",
"evt.inventory.failed",
"evt.inventory.released",
}
for _, subj := range subjects {
_, err := nc.Subscribe(subj, func(m *nats.Msg) {
var e Event
if err := json.Unmarshal(m.Data, &e); err != nil {
log.Println("bad event:", err)
return
}
sig := fmt.Sprintf("%s::%s", subj, e.SagaID)
log.Println("bridge -> signal", sig)
if err := c.SignalWorkflow(context.Background(), e.SagaID, "", sig, string(m.Data)); err != nil {
log.Println("signal err:", err)
}
})
if err != nil { log.Fatal(err) }
}
log.Println("signal-bridge running")
select {}
}
Why a separate process?
It keeps concerns clean: services don’t need to know Temporal exists; the workflow doesn’t need NATS code. The bridge is small, easy to scale, and easy to harden (DLQs, retries).
Services: dumb, predictable, testable
Each service just subscribes to cmd.* and publishes evt.*. They don’t hold saga state; they do their piece and tell the world what happened.
// services/payment/main.go
package main
import (
"encoding/json"
"log"
"demo-saga/pkg/util"
"github.com/nats-io/nats.go"
)
type Msg = util.Msg
func main() {
nc, err := util.ConnectNATS(); if err != nil { log.Fatal(err) }
defer nc.Close()
nc.Subscribe("cmd.payment.reserve", func(m *nats.Msg) {
var msg Msg; _ = json.Unmarshal(m.Data, &msg)
log.Println("[payment] reserve", util.MustJSON(msg))
// demo: always succeed
util.PublishJSON(nc, "evt.payment.reserved", msg)
})
nc.Subscribe("cmd.payment.refund", func(m *nats.Msg) {
var msg Msg; _ = json.Unmarshal(m.Data, &msg)
log.Println("[payment] refund", util.MustJSON(msg))
util.PublishJSON(nc, "evt.payment.refunded", msg)
})
log.Println("payment service running")
select {}
}
Starting the workflow (the CLI)
// cmd/start_workflow/main.go (excerpt)
opts := client.StartWorkflowOptions{
ID: "order-1", // the sagaId
TaskQueue: "ORDER_TASK_QUEUE",
}
in := workflows.OrderInput{
SagaID: "order-1", Amount: 100, SKU: "SKU-1", Qty: 1,
ShouldFailInventory: true, // flip to see compensation
}
we, err := c.ExecuteWorkflow(ctx, opts, workflows.OrderWorkflow, in)
Advantages of this structure
1) Signals keep the workflow honest.
We don’t pretend the workflow can “listen to NATS.” It can’t. With Signals, we model the truth: services publish events; someone needs to deliver them into the workflow. That someone is the bridge.
2) Activities are just command publishers.
They don’t wait for replies, they don’t block on I/O longer than necessary, and they’re idempotent. If we duplicate a command, the service should de-dupe based on sagaId. That’s realistic.
3) Correlation first, everything else second.
Every message has a sagaId. Signal names are "event::sagaId". That’s how we direct replies to the right workflow instance. This alone removes tons of accidental complexity.
4) Compensations belong to the orchestrator’s brain.
Services don’t “know” the saga; they just expose forward/undo endpoints through commands. The workflow decides when the undo happens, and Temporal makes the history visible so you can debug.
5) Separation of concerns ages well.
- Replace NATS with Kafka? Only the bridge and util code move.
- Add Shipping? New commands/events, same pattern.
- Switch to sync HTTP calls later? Replace Activities; the workflow orchestration stays the same.
Wrap-up
You now have a runnable, event-driven Saga with clear separation:
- Workflow: state machine + failure policy
- Activities: commands out
- Services: business actions + events out
- Bridge: events → workflow signals
This is the foundation you can take to production. Add shipping, swap NATS for Kafka, scale out the bridge, harden idempotency—you’ll still keep the same mental model.